
7.爬虫框架
Scrapy
安装
anaconda安装
如果已经安装好了 Anaconda,那么可以通过 conda 命令安装 Scrapy,安装命令如下:
conda install Scrapy运行之后便可以完成 Scrapy 的安装。
其他安装
pip install scrapy验证

用途
适用于抓取大量数据的时候。
文档
框架介绍
架构

scrapy架构可分为如下部分:
Engine 引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心
Item 项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该 Item 对象
Scheduler 调度器,接受引擎发过来的请求并将其放在队列中,在引擎再次请求的时候将请求提供给引擎
Downloader 下载器,下载网页内容,并将网页内容返回给蜘蛛
Spiders 蜘蛛,其内定义了爬取的逻辑和网页 解析规 ,它主要负责解析响应并生成提取结果和新的请求
Item Pipeline 项目管道,负责处理由蜘蛛从网页中 取的项目,它的主要任务是清洗、验证和存储数据
Downloader Middlewares 下载器中间件,位于引擎和下载器之 的钩子框架,主要处理引擎与下载器之间的请求及响应
Spide Middlewares 蜘蛛中间件,位于引擎和蜘蛛之 的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求
数据流
Scrapy 中的数据流由引擎控制,数据流的过程如下
Engine 引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心
Item 项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该 Item 对象
Scheduler 调度器,接受引擎发过来的请求并将其 列中 在引擎再次请求的时候将请求提供给引擎
Downloader 下载器,下载网页内容,并将网页 容返回给蜘蛛
Spiders 蜘蛛,其内定义了爬取的逻辑和网页 解析规 ,它主要负责解析响应并生成提取结果和新的请求
Item Pipeline 项目管道,负责处理由蜘蛛从网页中获取的项目,它的主要任务是清洗、验证和存储数据
Downloader Middlewares 下载器中间件,位于引擎和下载器之 的钩子框架,主要处理引擎与下载器之间的请求及响应
Spide Middlewares 蜘蛛中间件,位于引擎和蜘蛛之 的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求
项目结构
Scrapy 框架和pyspider不同,它是通过命令行来 建项目的,代码 编写还是需要 IDE, 项目
建之后,项目文件结构如下所示
scrapy.cfg
project
init.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
init .py
spider1.py
spider2.py
这里各个文件的功能描述如下:
scrapy.cfg: 它是Scrapy项目的配置文件,其内定义了项目的配置文件路径 部署相关信息等内容
items.py :它定义Item 数据结构,所有的 Item 的定义都可以放这里
pipelines.py: 它定义Item Pipeline 的实现,所有的 Item Pipeline 实现都可以放这里
settings.py: 它定义项目的全局配置
middlewares.py: 它定义 Spider Middlewares Downloader Middlewares
spiders: 其内包含 Spider 的实现,每个 Spider 都有一个文件
入门
创建项目
创建 Scrapy 项目,项目文件可以直接用 scrapy 命令生成
文件夹结构如下所示:

创建spider
Spider 是自定义的类, Scrapy 用它来从网页里抓取内容,并解析抓取的结果 不过这个类必须继承 Scrapy 提供的 Spider类 scrapy.Spider ,还要定义 Spider 的名称和起始请求,以及怎样处理爬取后的结果的方法。
使用命令行创建一个 Spider:

进入刚才创建的 myproject文件夹,然后执行 genspider 命令 第一个参数是 Spider 名称,第二个参数是网站域名 执行完毕之后, spiders 文件夹中多了一个 tff.py ,就是刚刚创建的 Spider。
这里有四个属性:name、allowed_domains 和 start_urls ,还有一个方法 parse。
name:是每个项目唯一的名字,用来区分不同的 Spider。allowe_domains:是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。start_urls:包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。parse:是 Spider 一个方法 默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数,该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
定义item
Item 是保存爬取数据的容器,使用方法和字典类似 不过,相比字典, Item 多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scrapy.Field 字段。
解析Response
parse()方法的参数resposne是start_urls 里面的链接爬取后的结果,所以在parse()方法中,可以直接对 response 变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。
提取的方式能够采用 css 选择器或 XPath 选择器。
::text:获取节点的正文内容extract_ first():获取第一个元素extract():获取所有元素,返回列表
使用item
Item可以理解为一个字典,不过在声明的时候需要实例,然后依次用刚才解析的结果赋值Item的每一个字 段, 后将Item返回即可。
运行爬虫
格式:
如下:

scrapy终端(scrapy shell)
scrapy shell能够很方便的进行调试代码,可以预先通过scrapy shell根据选择器来获取数据。
格式:
<url> 是要爬取的网页的地址
如下:
selectors选择器
这里选择采用xpath
xpath用法
nodename
选取此节点的所有子节点
/
从当前节点选取直接子节点
//
从当前节点选取子孙节点
.
选取当前节点
..
选取当前节点的父节点
@
选取属性
*
通配符,选择所有元素节点与元素名
@*
选取所有属性
[@attrib]
选取具有给定属性的所有元素
[@attrib='value]
选取给定属性具有给定值的所有元素
[tag]
选取所有具有指定元素的直接子节点
[tag="text"]
选取所有具有指定元素并且文本内容是text节点
构造选择器
使用python shell交互模式。
导入模块
构造数据
以字符串构造
以reponse构造
可以通过response对象以.selector属性方法,达到同样效果
使用选择器
打开shell
网站源码
提取数据
提取所有数据
获取属性id下的所有a标签的文本内容
提取第一个匹配的数据
获取属性id下的第一个a标签的文本内容
获取属性值
获取a标签的属性href的值
匹配内容
含有属性值href中值有"image"的所有标签下的href属性值
嵌套选择器
选择器方法( .xpath() )返回相同类型的选择器列表,因此可以对这些选择器调用选择器方法。
结合正则表达式使用选择器(selectors)
Selector 也有一个 .re() 方法,用来通过正则表达式来提取数据。然而,不同于使用 .xpath() 或者 .css() 方法, .re() 方法返回unicode字符串的列表。所以无法构造嵌套式的 .re() 调用。
Spiders用法
介绍
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作以及如何从网页的内容中提取结构化数据(爬取item)。
爬取步骤:
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生response,并作为参数传给该回调函数。
spider中初始的request是通过调用
start_requests()来获取的。start_requests()读取start_urls中的URL, 并以parse为回调函数生成Request。在回调函数内分析返回的(网页)内容,返回
Item对象、dict、Request或者一个包括三者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。 在回调函数内,可以使用 选择器(Selectors) (也可以使用BeautifulSoup, pyquery或者想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
scrapy.Spider
Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及自己编写的spider)。 Spider并没有提供什么特殊的功能。 其仅仅提供了 start_requests() 的默认实现,读取并请求spider属性中的 start_urls, 并根据返回的结果(resulting responses)调用spider的 parse 方法。
Splash
安装
安装Splash
ScrapySplash 会使用 Splash 的 HTTP API 进行页面渲染,所以需要安装 Splash 来提供渲染服务,安装是通过Docker进行安装,在这之前请确保已经正确安装好了 Docker。
安装命令如下:
安装完成之后会有类似的输出结果:
这样就证明 Splash 已经在 8050 端口上运行了。
这时打开:http://localhost:8050即可看到 Splash 的主页
当然 Splash 也可以直接安装在远程服务器上,在服务器上运行以守护态运行 Splash 即可,命令如下:
在这里多了一个 -d 参数,它代表将 Docker 容器以守护态运行,这样在中断远程服务器连接后不会终止 Splash 服务的运行。
用途
一个页面渲染服务器,返回渲染后的页面,便于爬取,便于规模应用。
文档
用法
实例

脚本语言内容:
wait():等待
html:返回页面的源码
png:返回页面的截图
HAR:返回页面的HAR信息
Splash Lua脚本
入口及返回值
通过spalsh:evaljs()方法传入javascript脚本。Splash默认调用main()方法方法的返回值为字典形式或者是字符串形式,最后都会转化为一个Splash HTTP Response
异步处理

wait():等待的描述..:字符串拼接操作符ipairs():操作字典进行迭代
Splash对象属性
args
splash对象的args属性可以获取加载时配置的参数
运行结果:
js_endabled
js_endabled属性是splash的javascript执行开关,可以将其配置为True或False来控制是否可以执行JavaScript代码,默认为True
禁用之后,调用evaljs()方法执行javascript代码,会抛出异常
一般情况下默认开启
resoure_timeout
设置加载的超时时间,单位为秒数。如果设置为0或nil就表示不检测超时
设置超时为0.1秒,如果在0.1秒之内没有得到响应就会抛出异常

images_enabled
设置图片是否加载
plugins_enabled
控制浏览器插件是否开启,如Flash。默认情况下事是False/不开启
scroll_position
控制页面的滚动偏移
splash.scroll_position = {x=x,y=y}
Splash对象方法
go()
go():用来请求某个链接的方法,可以模拟GET和POST请求,同时支持传入Headers、From Data等数据
参数说明:
url:请求的url
baseurl:资源加载相对路径
headers:请求的headers
http_method:默认是get,同时支持post
body:post的时候的表单数据,使用的Content-type为application
fromdata:post的时候表单数据,使用的Content-type为application/x-www-form-urlencoded
返回的结果是结果ok和原因reason的组合,如果ok为空,代表网页加载出现了错误,此时reason变量中包含了错误的原因,否则证明页面加载成功
模拟post请求,并传入POST的表单数据,如果成功,则返回用页面源代码
运行结果:
wait()
控制页面等待时间
参数说明:
time:等待秒数
cancel_on_redirect:默认Fasle,如果发生了重定向就停止等待,并返回重定向结果
cancel_on_error:默认False,如果加载发生了加载错误就停止等待
jsfunc()
直接调用javascript定义的方法,需要用双中括号包围,相等于实现了javascript方法到lua脚本的转换
运行结果:
evaljs()
执行javascript代码并返回最后一条语句的返回结果
runjs()
执行JavaScript代码类似于evaljs()功能类似,但偏向于执行某些动作或声明某些方法evaljs()偏向于获取某些执行结果
运行结果:
autoload()
设置每个页面访问时自动加载的对象
参数说明:
source_or_url:JavaScript代码或者JavaScript库链接
source,JavaScript代码
url,JavaScript库链接
只负责加载JavaScript代码或库,不执行任何操作,如果要执行操作可以调用evaljs()或runjs()方法
运行结果:
加载某些方法库,如JQuery
运行结果:
call_later()
可以通过设置定时任务和延迟时间实现任务延时执行,并且可以在执行前通过 cancel() 方法重新执行定时任务
http_get()
此方法可以模拟发送 HTTP 的 GET 请求,使用方法如下:
参数说明如下:
url,请求URL。
headers,可选参数,默认为空,请求的 Headers。
follow_redirects,可选参数,默认为 True,是否启动自动重定向。
http_post()
和 http_get() 方法类似,此方法是模拟发送一个 POST 请求,不过多了一个参数 body,使用方法如下
参数说明如下:
url,请求URL。
headers,可选参数,默认为空,请求的 Headers。
follow_redirects,可选参数,默认为 True,是否启动自动重定向。
body,可选参数,默认为空,即表单数据。
set_content()
此方法可以用来设置页面的内容
html()
此方法可以用来获取网页的源代码
png()
此方法可以用来获取 PNG 格式的网页截图
jpeg()
此方法可以用来获取 JPEG 格式的网页截图
har()
此方法可以用来获取页面加载过程描述
url()
此方法可以获取当前正在访问的 URL
get_cookies()
此方法可以获取当前页面的 Cookies
add_cookie()
此方法可以为当前页面添加 Cookie
clear_cookies()
此方法可以清除所有的 Cookies
get_viewport_size()
此方法可以获取当前浏览器页面的大小,即宽高
set_viewport_size()
此方法可以设置当前浏览器页面的大小,即宽高
set_viewport_full()
此方法可以设置浏览器全屏显示
set_user_agent()
此方法可以设置浏览器的 User-Agent
set_custom_headers()
此方法可以设置请求的 Headers
select()
select() 方法可以选中符合条件的第一个节点,如果有多个节点符合条件,则只会返回一个,其参数是 CSS 选择器

select_all()
此方法可以选中所有的符合条件的节点,其参数是 CSS 选择器
mouse_click()
此方法可以模拟鼠标点击操作,传入的参数为坐标值 x、y,也可以直接选中某个节点直接调用此方法

Splash API调用
render.html
用于获取javascript渲染页面的HTML代码
render.png
获取网页截图
参数:
height:高
width:宽
图片:https://splash.readthedocs.io/en/stable/api.html#render-png
render.har
此接口用于获取页面加载的 HAR 数据
返回结果非常多,是一个 Json 格式的数据,里面包含了页面加载过程中的 HAR 数据。
render.json
此接口包含了前面接口的所有功能,返回结果是 Json 格式
更多参数:https://splash.readthedocs.io/en/stable/api.html#render-json
execute
此接口可以实现和 Lua 脚本的对接
Pyspider
安装
创建虚拟环境python版本为python3.6
激活虚拟环境
删除虚拟环境
查看已有虚拟环境
Windows 下可能会出现这样的错误提示:
这是pycurl安装错误,需要安装pucurl下载地址,找到与之对应的wheel文件。
如Windows 64 位,Python3.6 则下载 pycurl‑7.43.0‑cp36‑cp36m‑win_amd64.whl
Linux 下如果遇到 PyCurl 的错误:
解决方案:
运行安装后即可正常安装pycurl。
验证,启动pyspider
控制平台如下输出:
报错,接下来,进行解决这个问题。
解决方法:按照报错的路径,找到anaconda\lib\site-packages\pyspider,进入后将run.py中的async查找,全部替换为_async。之后对同目录下其他文件夹中的py文件执行相同的操作。替换时要注意大小写,只替换async单个单词为_async。
在替换是要注意:只替换名为async 的变量或参数名。不要图省事选择“全部替换”
重新运行,发现报如下错误:
发现主要是werkzeug版本不对的问题
若出现如下错误:
解决:
找到安装包python36->Lib->site-packages->pyspider->webui->webdav.py。如下图: 修改209行代码,如下:
修改为:
因为版本不兼容,所以替换为2.4.1
如果一直卡在result_worker starting…,在原窗口不关闭的情况下,重新打开另外一个窗口进行输入pyspider之后进行关闭,就能够成功运行,如果不行,可以重新打开窗口,反复几次操作下。
如果不行,就去杀死pyspider进程


用途
PySpider带有强大的WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,它支持多种数据库后端、多种消息队列、Javascript渲染页面的爬取,使用起来非常的方便。
PySpider的基本功能:
提供方便易用的 WebUI 系统,可视化地编写和调式爬虫
提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
支持多种后端数据库,如 MySQL、MongoDB、Reids、SQLite、Elasticsearch、PostgreSQL。
支持多种消息队列、如 RabbitMQ、Beanstalk、Redis、Kombu。
提供优先级控制、失败重试、定时抓取等功能。
对接了 PhantomJS、可以抓取 JavaScript 渲染的页面。
支持单机和分布式部署、支持 Docker 部署。
PySpider的设计基础是:
以python脚本驱动的抓取环模型爬虫
通过python脚本进行结构化信息的提取,follow链接调度抓取控制,实现最大的灵活性
通过web化的脚本编写、调试环境。web展现调度状态
抓取环模型成熟稳定,模块间相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展
PySpider与Scrapy的比较:
PySpider提供了WebUI,爬虫的编写、调试都是再WebUI中进行。而Scrapy原生是不具备这些功能的,它采取的是代码和命令行操作,但是可通过Portia实现可视化配置。
PySpider调试非常的方便。WebUI操作便捷直观。Scrapy则是使用parse命令进行调试,其方便程度不及PySpider。
PySpider支持PhantomJS来进行Javascript渲染也买你的额采集。Scrapy可以对接Scrapy-Splash组件,这需要额外配置。
PySpider内置了PyQuery作为选择器,Scrapy对接了XPath、CSS选择器和正则匹配。
PySpider的可扩展程度不足,可配置化程度不高。Scrapy可通过对接Middleware、Pipeline、Extension等组件实现非常强大的功能,模块之间的耦合程度低,可扩展程度极高。
如果想要快速方便地实现一个页面的抓取,使用 pyspider 不失为一个好的选择。如快速抓取某个普通新闻网站的新闻内容。但如果应对反爬程度很强、超大规模的抓取、推荐使用 Scrapy、如抓取封 IP、封账号、高频验证的网站的大规模数据采集。
文档
框架介绍
PySpider 的架构主要分为 Scheduler(调度器)、Fetcher(抓取器)、Processer(处理器)三个部分。整个爬取过程受到 Monitor(监控器)的监控,抓取的结果被 Result Worker(结果处理器)处理。

Scheduler 发起任务调度,Fetcher 负责抓取网页内容,Processer 负责解析网页内容,然后将新生成的 Request 发给 Scheduler 进行调度,将生成的提取结果输出保存。
模块
功能
WebUI
web的可视化任务监控web脚本编写,单步调试异常捕获,log捕获,print捕获等
Scheduler
任务优先级周期定时任务流量控制基于时间周期 或 前链标签(例如更新时间)的重抓取调度
Fetcher
dataurl支持,用于假抓取模拟传递method, header, cookie, proxy, etag, last_modified, timeout等抓取调度控制通过适配类似 phantomjs 的webkit引擎支持渲染
Processer
内置的pyquery,以jQuery解析页面在脚本中完全控制调度抓取的各项参数,向后链传递信息异常捕获
PySpider 的任务执行流程的逻辑很清晰,具体过程如下所示:
每个 PySpider项目对应一个 Python 脚本,该脚本定义了一个 Handler 类,它有一个 on_start() 方法。爬取首先调用 on_start() 方法生成最初的抓取任务,然后发送给 Scheduler。
Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并得到响应、随后将响应发送给 Processer。
Processer 处理响应并提取出新的 URL 生成新的抓取任务,然后通过消息队列的方式通知 Scheduler 当前抓取任务执行情况,并将新生成的抓取任务发送给 Scheduler。如果生成了新的提取结果,则将其发送到结果队列等待 Result Worker 处理。
Scheduler 接收到新的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其发送回 Fetcher 进行抓取。
不断重复以上工作、直到所有的任务都执行完毕,抓取结束。
抓取结束后、程序会回调 on_finished() 方法,这里可以定义后处理过程。
基本使用
目标
爬取去哪儿旅游网站,并且将网页中的作者,标题等内容,存到到MongoDB中。
启动pyspider
可以打开浏览器,输入链接 http://localhost:5000,会看到WebUI页面,能够用来管理项目、编写代码、在线调试、监控任务等。

创建项目
新建一个项目,点击右边的 Create 按钮,在弹出的浮窗里输入项目的名称和爬取的链接,再点击 Create 按钮,就能够成功创建一个项目。

接下来会看到 pyspider 的项目编辑和调试页面用法详解

左侧就是代码的调试页面,点击左侧右上角的 run 单步调试爬虫程序;在左侧下半部分可以预览当前的爬取页面;右侧是代码编辑页面,可以直接编辑代码和保存代码,不需要借助于 IDE。
注意右侧,pyspider 已经生成了一段代码,代码如下所示:
详解用法
Handler
pyspider 爬虫的主类,可以在此处定义爬取、解析、存储的逻辑。整个爬虫的功能只需要一个 Handler 即可完成。
crawl_config 属性
可以将本项目的所有爬取配置统一定义到这里,如定义 Headers、设置代理等,配置之后全局生效。
on_start() 方法
爬取入口,初始的爬取请求会在这里产生,该方法通过调用 crawl() 方法即可新建一个爬取请求,第一个参数是爬取的 URL,这里自动替换成所定义的 URL。crawl() 方法还有一个参数 callback,它指定了这个页面爬取成功后用哪个方法进行解析,代码中指定为 index_page() 方法,即如果这个 URL 对应的页面爬取成功了,那 Response 将交给 index_page() 方法解析。
index_page() 方法
接收这个 Response 参数,Response 对接了 pyquery。直接调用 doc() 方法传入相应的 CSS 选择器,就可以像 pyquery 一样解析此页面,代码中默认是 a[href^=”http”],也就是说该方法解析了页面的所有链接,然后将链接遍历,再次调用了 crawl() 方法生成了新的爬取请求,同时再指定了 callback 为 detail_page,意思是说这些页面爬取成功了就调用 detail_page() 方法解析。这里,index_page() 实现了两个功能,一是将爬取的结果进行解析,二是生成新的爬取请求。
detail_page()
同样接收 Response 作为参数。detail_page() 抓取的就是详情页的信息,就不会生成新的请求,只对 Response 对象做解析,解析之后将结果以字典的形式返回。也可以进行后续处理,如将结果保存到数据库。
爬取首页
点击左栏右上角的 run 按钮,即可看到页面下方 follows 便会出现一个标注,其中包含数字 1,这代表有新的爬取请求产生。
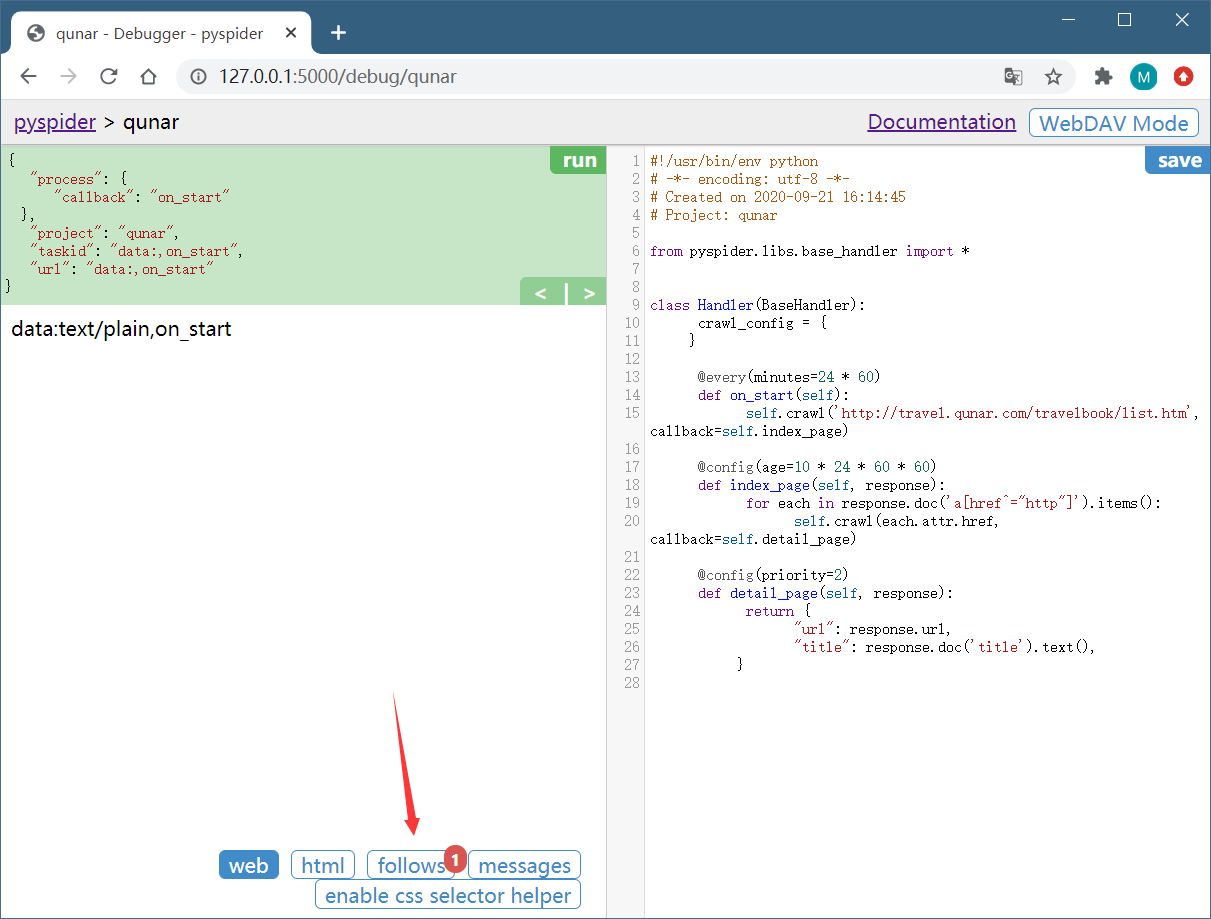
左栏左上角会出现当前 run 的配置文件,这里有一个 callback 为 on_start,这说明点击 run 之后实际是执行了 on_start() 方法。在 on_start() 方法中,利用 crawl() 方法生成一个爬取请求,那下方 follows 部分的数字 1 就代表了这一个爬取请求。
点击下方的 follows 按钮,即可看到生成的爬取请求的链接。每个链接的右侧还有一个箭头按钮。

点击该箭头,就可以对此链接进行爬取,也就是爬取的首页内容。
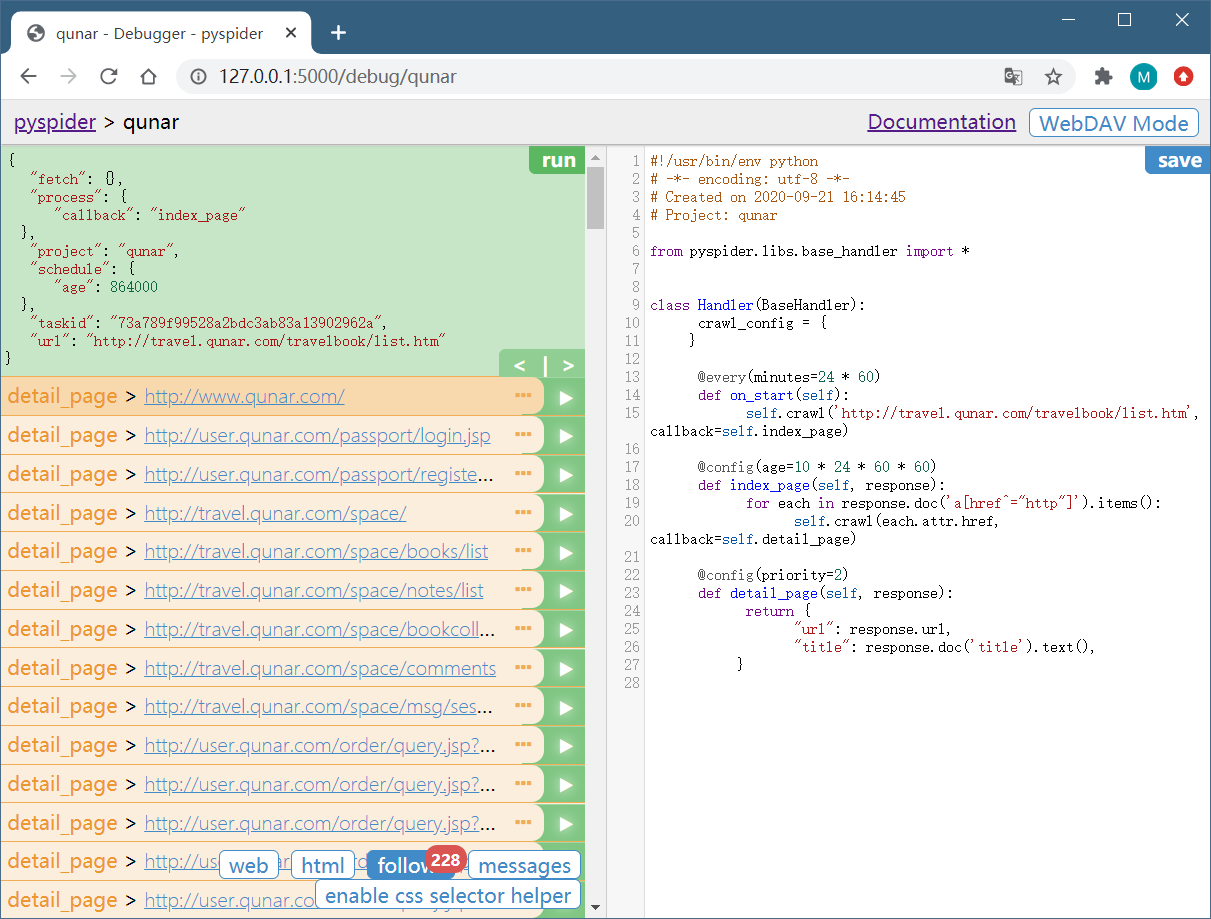
上方的 callback 已经变成了 index_page,这就代表当前运行了 index_page() 方法。index_page() 接收到的 response 参数就是刚才生成的第一个爬取请求的 Response 对象。index_page() 方法通过调用 doc() 方法,传入提取所有 a 节点的 CSS 选择器,然后获取 a 节点的属性 href,这样实际上就是获取了第一个爬取页面中的所有链接。然后在 index_page() 方法里遍历了所有链接,同时调用 crawl() 方法,就把这一个个的链接构造成新的爬取请求了。所以最下方 follows 按钮部分有 228 的数字标记,这代表新生成了 228 个爬取请求,同时这些请求的 URL 都呈现在当前页面了。
再点击下方的 web 按钮,即可预览当前爬取结果的页面。

当前看到的页面结果和浏览器看到的几乎是完全一致的,在这里可以方便地查看页面请求的结果。
如果pyspider WEB显示框太小,解决如下:
WEB预览框过小的原因在于页面元素的css属性height被替换为60px;
CSS文件所在地方:..\Lib\site-packages\pyspider\webui\static\debug.min.css
打开此文件,搜索iframe,将其修改为:
因为注明了!important,所以height=900不会被替换,修改后如下图:

最后,因为 pyspider 有缓存机制,虽然替换了css文件,如果没有清空缓存的话pyspider还是使用原来的css文件。所以记得浏览器清空缓存。清空浏览器缓存后重启浏览器就可以看到正常的WEB大小了。

点击 html 按钮即可查看当前页面的源代码

刚才在 index_page() 方法中提取了所有的链接并生成了新的爬取请求。但是很明显要爬取的肯定不是所有链接,只需要攻略详情的页面链接就够了,所以要修改一下当前 index_page() 里提取链接时的 CSS 选择器。
接下来需要另外一个工具。首先切换到 Web 页面,找到攻略的标题,点击下方的 enable css selector helper,点击标题。这时候看到标题外多了一个红框,上方出现了一个 CSS 选择器,这就是当前标题对应的 CSS 选择器。
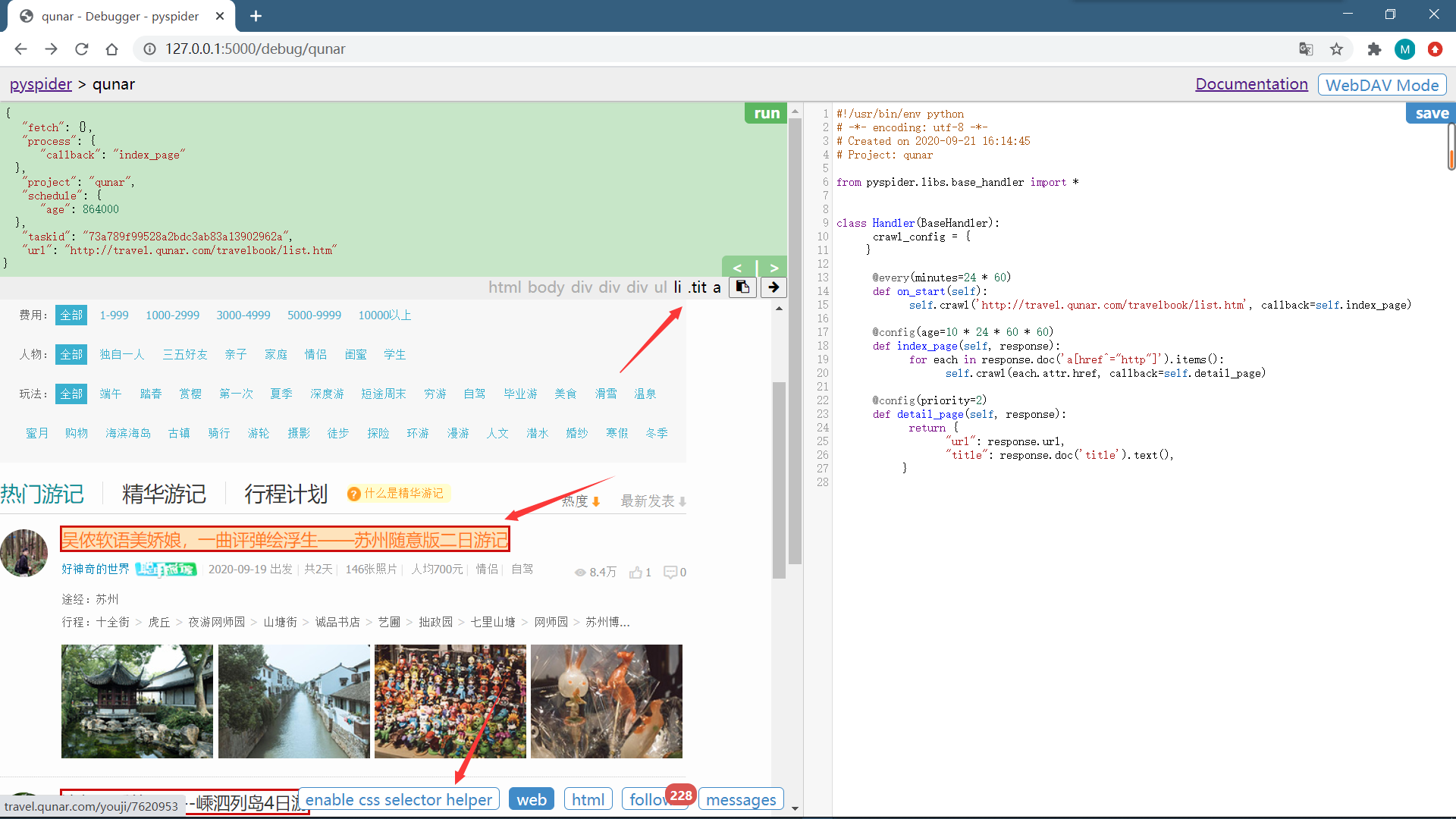
在右侧代码选中要更改的区域,点击左栏的右箭头,此时在上方出现的标题的 CSS 选择器就会被替换到右侧代码中

重新点击左栏右上角的 run 按钮,即可重新执行 index_page() 方法。此时的 follows 就变成了 10 个。
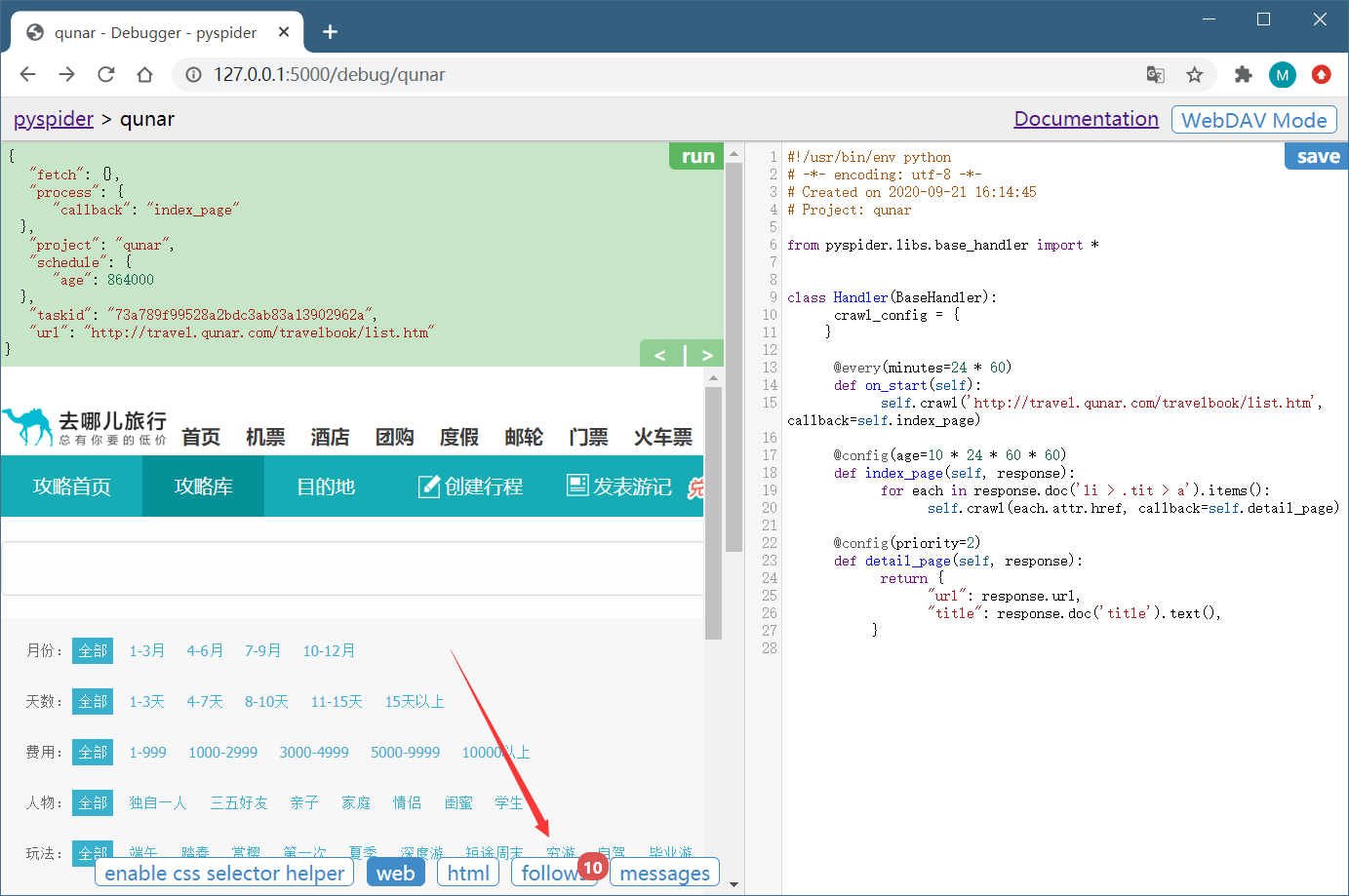
现在抓取的只是第一页的内容,还需要抓取后续页面,所以还需要一个爬取链接,即爬取下一页的攻略列表页面。再利用 crawl() 方法添加下一页的爬取请求,在 index_page() 方法里面添加如下代码,然后点击 save 保存:
利用 CSS 选择器选中下一页的链接,获取它的 href 属性,也就获取了页面的 URL。然后将该 URL 传给 crawl() 方法,同时指定回调函数,注意这里回调函数仍然指定为 index_page() 方法,因为下一页的结构与此页相同。
重新点击 run 按钮,这时就可以看到 11 个爬取请求。follows 按钮上会显示 11,这就代表成功添加了下一页的爬取请求。

爬取详情页
任意选取一个详情页进入,点击10 个爬取请求中的任意一个的右箭头,执行详情页的爬取。
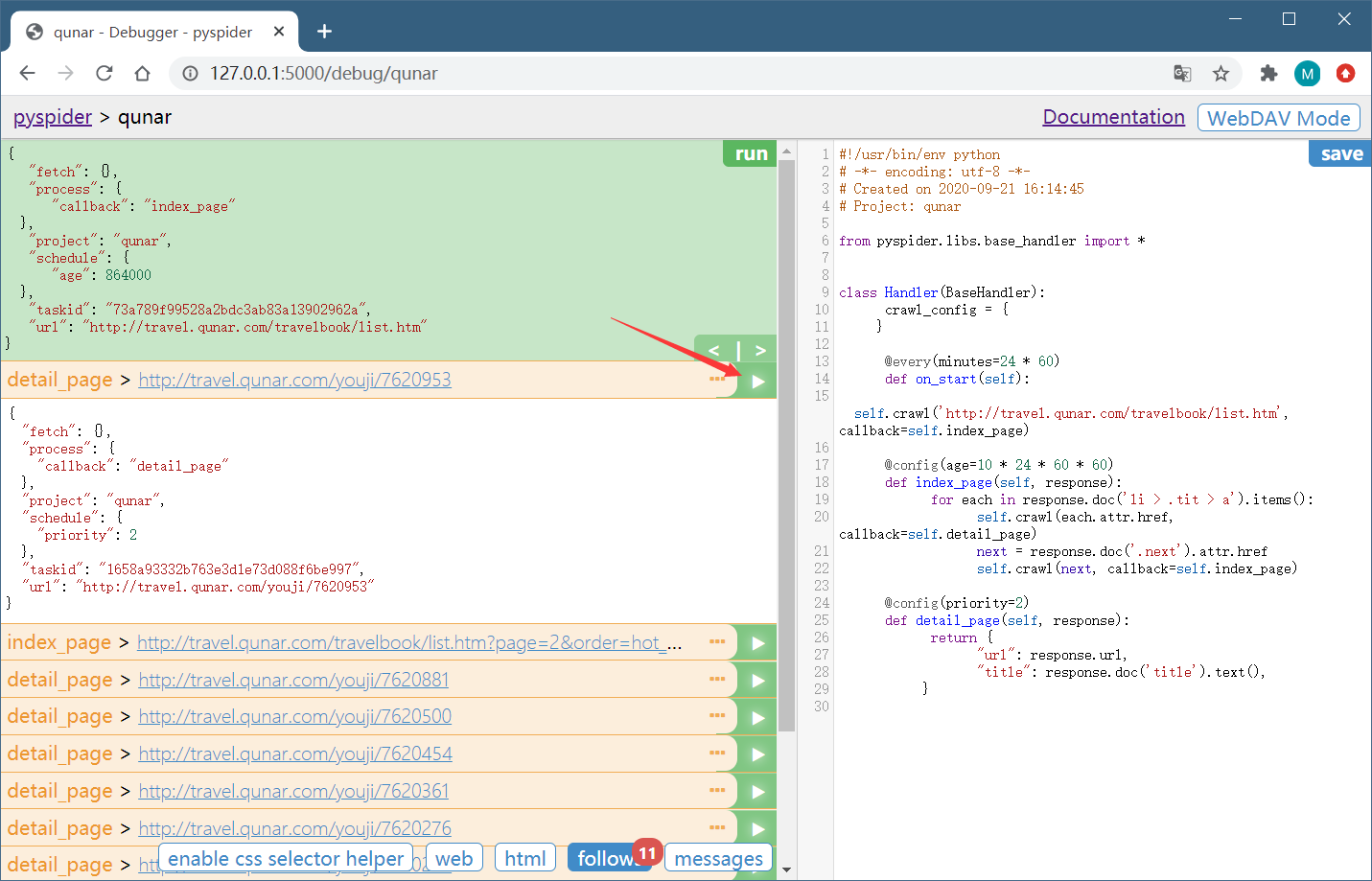
切换到 Web 页面预览效果,页面下拉之后,头图正文中的一些图片一直显示加载中。

出现此现象的原因是 pyspider 默认发送 HTTP 请求,请求的 HTML 文档本身就不包含 img 节点。但是在浏览器中看到了图片,这是因为这张图片是后期经过 JavaScript 出现的。那么,该如何获取?
由于,pyspider 内部对接了 PhantomJS,只需要修改一个参数即可。
将 index_page() 中生成抓取详情页的请求方法添加一个参数 fetch_type,改写的 index_page() 变为如下内容:
点击左栏上方的左箭头返回,重新调用 index_page() 方法生成新的爬取详情页的 Request

再点击新生成的详情页 Request 的爬取按钮,图片就能够加载出来了。

最后就是将详情页中需要的信息提取出来,通过改写最detail_page() 方法,如下:
重新运行
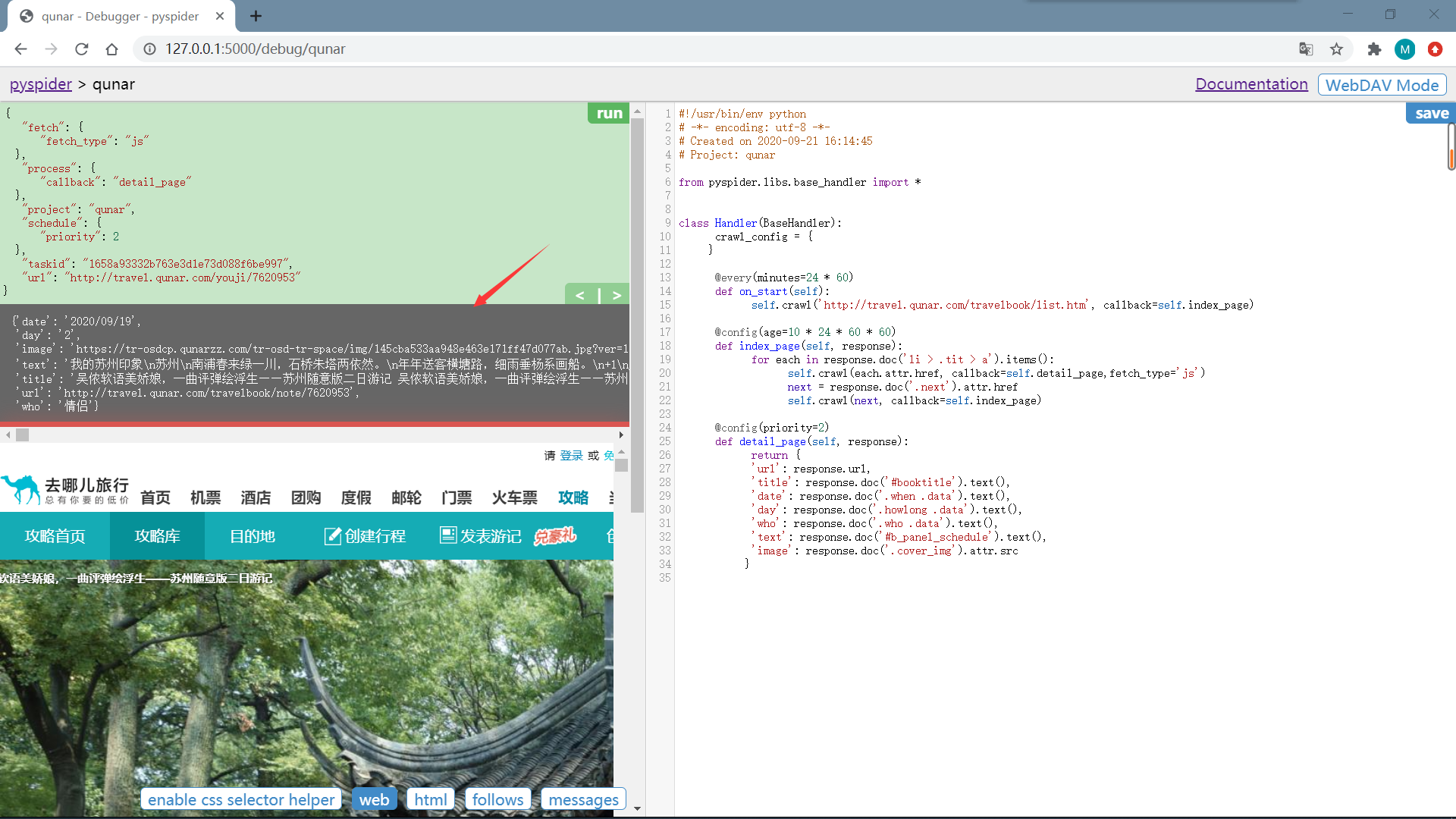
启动爬虫
返回爬虫的主页面,将爬虫的 status 设置成 DEBUG 或 RUNNING,点击右侧的 Run 按钮即可开始爬取。

在最左侧可以定义项目的分组,以方便管理。
rate/burst 代表当前的爬取速率
rate 代表 1 秒发出多少个请求
burst 相当于流量控制中的令牌桶算法的令牌数
rate 和 burst 设置的越大,爬取速率越快,当然速率需要考虑本机性能和爬取过快被封的问题。
process 中的 5m、1h、1d 指的是最近 5 分、1 小时、1 天内的请求情况
all 代表所有的请求情况,请求由不同颜色表示。
蓝色的代表等待被执行的请求
绿色的代表成功的请求
黄色的代表请求失败后等待重试的请求
红色的代表失败次数过多而被忽略的请求
这样可以直观知道爬取的进度和请求情况。

点击 Active Tasks,即可查看最近请求的详细状况

点击 Results,即可查看所有的爬取结果
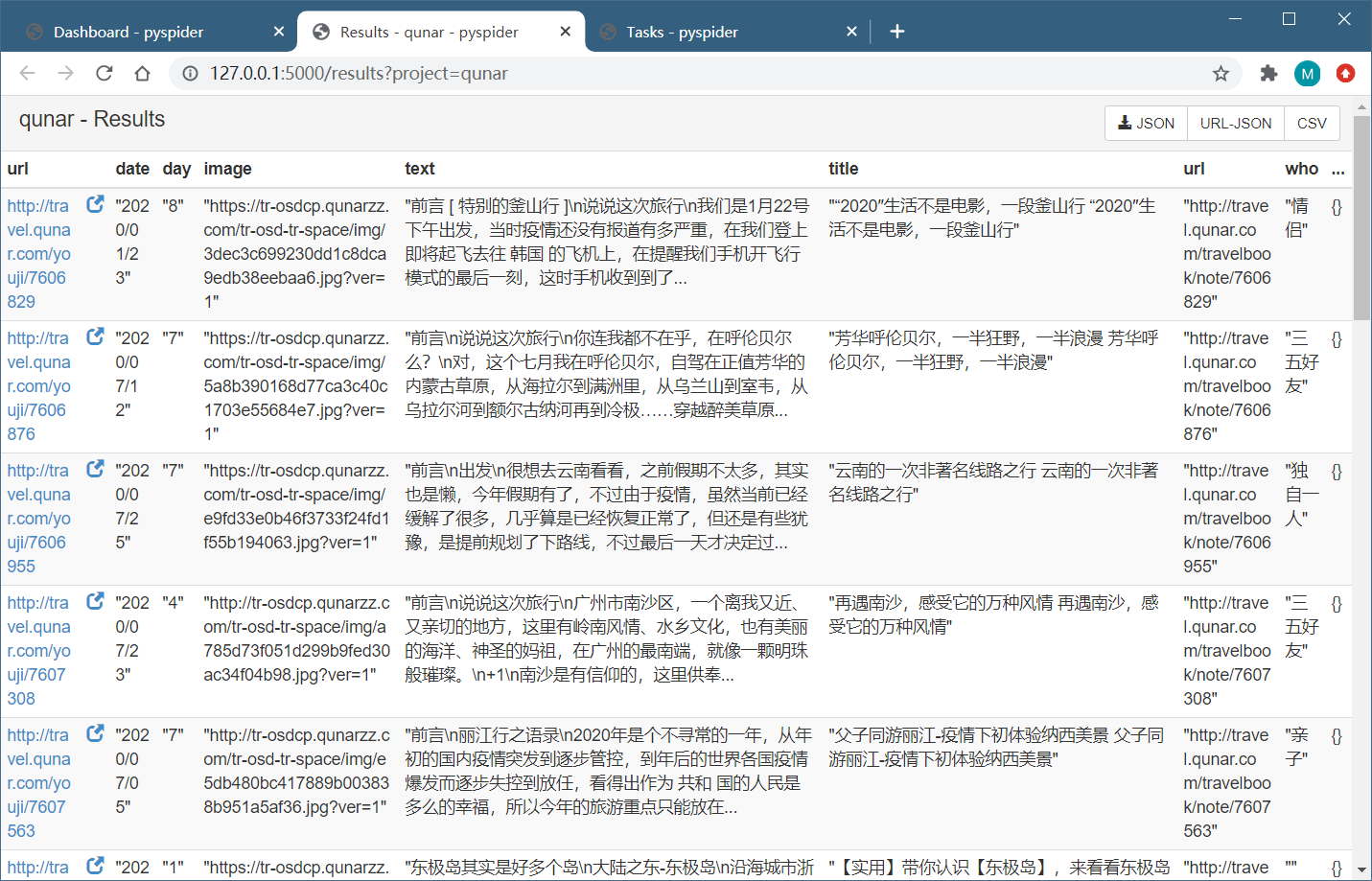
点击右上角的按钮,即可获取数据的 JSON、CSV 格式。
用法详解
命令行详解
命令行还有很多可配制参数,完整的命令行结构如下所示:
其中,OPTIONS 为可选参数,它可以指定如下参数。
例如,-c 可以指定配置文件的名称,这是一个常用的配置,配置文件的样例结构如下所示:
如果要配置 pyspider WebUI 的访问认证,可以新建一个 pyspider.json,内容如下所示:
通过在启动时指定配置文件来配置 pyspider WebUI 的访问认证,用户名为 root,密码为 123456,命令如下所示:
运行 Scheduler 的命令如下所示:
运行时也可以指定各种配置,参数如下所示:
运行 Fetcher 的命令如下所示:
参数配置如下所示:
运行 Processer 的命令如下所示:
参数配置如下所示:
运行 WebUI 的命令如下所示:
参数配置如下所示:
这里的配置和前面提到的配置文件参数是相同的。如果想要改变 WebUI 的端口为 5001,单独运行如下命令:
或者可以将端口配置到 JSON 文件中,配置如下所示:
使用如下命令启动同样可以达到相同的效果:
这样就可以在 5001 端口上运行 WebUI 了。
crawl()方法
格式:
url
爬取时的 URL,可以定义为单个 URL 字符串,也可以定义成 URL 列表。
callback
回调函数,指定了该 URL 对应的响应内容通过使用哪个方法来解析。
age
任务的有效时间。如果某个任务在有效时间内且已经被执行,则它不会重复执行。可以通过config进行设置,例如:@config(age=10 * 24 * 60 * 60)。
priority
爬取任务的优先级,其值默认是 0,priority 的数值越大,对应的请求会越优先被调度。
exetime
可以设置定时任务,其值是时间戳,默认是 0,即代表立即执行。例如:exetime=time.time()+30*60。
retries
定义重试次数,其值默认是 3。
itag
设置判定网页是否发生变化的节点值,在爬取时会判定次当前节点是否和上次爬取到的节点相同。如果节点相同,则证明页面没有更新,就不会重复爬取。例如:itag=item.find('.update-time').text()。
auto_recrawl
当值为True时,爬取任务在过期后会重新执行,循环时间即定义的 age 时间长度。
method
HTTP 请求方式,它默认是 GET。如果想发起 POST 请求,可以将 method 设置为 POST。
params
GET 请求参数,配合method使用。
data
POST 表单数据。当请求方式为 POST 时,可以通过此参数传递表单数据,配合method使用。
files
上传的文件,需要指定文件名,配合method使用。
user_agent
爬取使用的 User-Agent
headers
Request Headers
cookies
爬取时使用的 Cookies,为字典格式
connect_timeout
在初始化连接时的最长等待时间,它默认是 20 秒
timeout
抓取网页时的最长等待时间,默认是 120 秒。
allow_redirects
确定是否自动处理重定向,默认是 True
validate_cert
确定是否验证证书,此选项对 HTTPS 请求有效,默认是 True。
proxy
爬取时使用的代理,它支持用户名密码的配置,格式为 username:password@hostname:port。可以设置 craw_config 来实现全局配置,
fetch_type
开启 PhantomJS 渲染。如果遇到 JavaScript 渲染的页面,指定此字段即可实现 PhantomJS 的对接,pyspider 将会使用 PhantomJS 进行网页的抓取。
js_script
页面加载完毕后执行的 JavaScript 脚本。例如:js_script='''function() {window.scrollTo(0,document.body.scrollHeight); return 123; } '''
js_run_at
代表 JavaScript 脚本运行的位置,是在页面节点开头还是结尾,默认是结尾,即 document-end。
js_viewport_width/js_viewport_height
JavaScript 渲染页面时的窗口大小。
load_images
加载 JavaScript 页面时确定是否加载图片,它默认是否
save
可以在不同的方法之间传递参数。
cancel
取消任务,如果一个任务是 ACTIVE 状态的,则需要将 force_update 设置为 True。
force_update
即使任务处于 ACTIVE 状态,那也会强制更新状态。
任务区分
在 pyspider 判断两个任务是否是重复的是使用的是该任务对应的 URL 的 MD5 值作为任务的唯一 ID,如果 ID 相同,那么两个任务就会判定为相同,其中一个就不会爬取了。很多情况下请求的链接可能是同一个,但是 POST 的参数不同。这时可以重写 task_id() 方法,改变这个 ID 的计算方式来实现不同任务的区分,如下所示:
这里重写了 get_taskid() 方法,利用 URL 和 POST 的参数来生成 ID。这样一来,即使 URL 相同,但是 POST 的参数不同,两个任务的 ID 就不同,它们就不会被识别成重复任务。
全局配置
pyspider 可以使用 crawl_config 来指定全局的配置,配置中的参数会和 crawl() 方法创建任务时的参数合并。如要全局配置一个 Headers,可以定义如下代码:
定时爬取
可以通过 every 属性来设置爬取的时间间隔,如下所示:
由于在有效时间内爬取不会重复。所以要把有效时间设置得比重复时间更短,这样才可以实现定时爬取。
例如,下面的代码就无法做到每天爬取:
这里任务的过期时间为 10 天,而自动爬取的时间间隔为 1 天。当第二次尝试重新爬取的时候,pyspider 会监测到此任务尚未过期,便不会执行爬取,所以需要将 age 设置得小于定时时间。
项目状态
每个项目都有 6 个状态,分别是 TODO、STOP、CHECKING、DEBUG、RUNNING、PAUSE。
TODO:它是项目刚刚被创建还未实现时的状态。
STOP:如果想停止某项目的抓取,可以将项目的状态设置为 STOP。
CHECKING:正在运行的项目被修改后就会变成 CHECKING 状态,项目在中途出错需要调整的时候会遇到这种情况。
DEBUG/RUNNING:这两个状态对项目的运行没有影响,状态设置为任意一个,项目都可以运行,但是可以用二者来区分项目是否已经测试通过。
PAUSE:当爬取过程中出现连续多次错误时,项目会自动设置为 PAUSE 状态,并等待一定时间后继续爬取。
删除项目
pyspider 中没有直接删除项目的选项。如要删除任务,那么将项目的状态设置为 STOP,将分组的名称设置为 delete,等待 24 小时,则项目会自动删除。
最后更新于
这有帮助吗?