
2.请求模块的使用
requests
安装
pip install requests用途
用于模拟请求网页链接,从而获得数据。
相关文档
基本用法
Response
import requests
r = requests.get('https://www.baidu.com/')
print(type(r.status_code), r.status_code)
print(type(r.headers), r.headers)
print(type(r.cookies), r.cookies)
print(type(r.url), r.url)
print(type(r.history), r.history)response.cookies:网页的cookies
response.text:网页的文本内容
response.status_code:网页的状态码
response.history:请求历史
response.url:网页URL
运行结果:
Status Code 常用来判断请求是否成功,Requests 还提供了一个内置的 Status Code 查询对象 requests.codes。
返回码和相应的查询条件:
get请求
没有参数
测试连接:http://httpbin.org/get,会判断如果如果是 GET 请求的话,会返回响应的 Request 信息。
运行结果:
如果返回的内容为json数据可以,通过respons.json()进行打印数据,这样返回的格式为json格式。
有参数
可以通过在url里面添加参数,但是这样有点麻烦,而requests里面可以通过params进行处理。
运行结果:
获取二进制数据
图片、音频、视频这些文件都是本质上由二进制码组成的,由于有特定的保存格式和对应的解析方式,才可以看到这些形形色色的多媒体。所以想要抓取,那就需要拿到二进制码。
以 GitHub 的站点图标为例
在爬取二进制数据时,应该使用content属性。
运行结果:
接下来将二进制数据,保存为图片
运行后,会在同一目录下生产图标

添加Headers
通过requests里面的headers参数,就可以添加headers了。
实际情况下,添加headers有时候需要添加很多
如下:

可以观察到,请求头的格式为A:B,由于粘贴复制过来后,还是需要进行修改为字典形式,有点麻烦。接下来就动手弄一个方便转化headers的python代码。
运行结果:
解析headers的代码,如下:
这样就能够直接粘贴复制headers过来,自动解析为字典形式了。
post请求
post方法与get方法基本用法一样,只是请求方式不同。
没有表单数据
有表单数据
通过data传递表单数据。
其他请求方式
高级用法
上传文件
通过files关键字参数进行上传二进制数据,即文件。
Cookies
获取cookies
运行结果:
通过使用cookies来维持登录
cookies在请求头里面进行设置的。
当然也可以通过 cookies 参数来设置,不过这样就需要构造 RequestsCookieJar 对象,而且需要分割一下 Cookies ,相对繁琐,不过效果是相同的,实例如下:
新建了一个 RequestCookieJar 对象
将复制下来的 Cookies 利用 split() 方法分割,利用 set() 方法设置好每一个 Cookie 的 key 和 value
通过调用 Requests 的 get() 方法并传递给 cookies 参数即可,当然由于知乎本身的限制, headers 参数也不能少,只不过不需要在原来的 headers 参数里面设置 Cookie 字段了
会话维持
测试网址:http://httpbin.org/cookies/set/number/123456789
解决这个问题的主要方法就是维持同一个会话,也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器。但是又不想每次设置 Cookies,那该怎么办?这时候就有了新的利器 Session对象。
利用它,可以方便地维护一个会话,而且不用担心 Cookies 的问题,它会自动处理好
运行结果:
不能成功获取到设置的 Cookies
使用session测试
运行结果:
利用 Session 可以做到模拟同一个会话,而且不用担心 Cookies 的问题,通常用于模拟登录成功之后再进行下一步的操作。
SSL证书验证
测试网址:https://www.12306.cn
Requests 提供了证书验证的功能,当发送 HTTP 请求的时候,它会检查 SSL 证书,可以使用 verify 这个参数来控制是否检查此证书,其实如果不加的话默认是 True,会自动验证。
运行结果:
提示一个错误,叫做 SSLError,证书验证错误。所以如果请求一个 HTTPS 站点,但是证书验证错误的页面时,就会报这样的错误
如何避免这个错误,只需把 verify 这个参数设置为 False 即可。
运行结果:
不过发现报了一个警告,它提示建议给它指定证书。
可以通过设置忽略警告的方式来屏蔽这个警告:
运行结果:
或者通过捕获警告到日志的方式忽略警告:
可以指定一个本地证书用作客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组
代理设置
设置代理,在 Requests 中需要用到 proxies 这个参数
若代理需要使用 HTTP Basic Auth,可以使用类似http://user:password@host:port这样的语法来设置代理
除了基本的 HTTP 代理,Requests 还支持 SOCKS 协议的代理。
需要安装 Socks 这个库,命令如下:
然后就可以使用 SOCKS 协议代理了
超时设置
设置超时时间需要用到 timeout 参数。这个时间的计算是发出 Request 到服务器返回 Response 的时间
通过这样的方式,可以将超时时间设置为 1 秒,如果 1 秒内没有响应,那就抛出异常。
实际上请求分为两个阶段,即 connect(连接)和 read(读取)。
上面的设置 timeout 值将会用作 connect 和 read 二者的 timeout 总和。
如果要分别指定,就可以传入一个元组:
如果想永久等待,那么可以直接将 timeout 设置为 None,或者不设置直接留空,因为默认是 None。这样的话,如果服务器还在运行,但是响应特别慢,那就慢慢等吧,它永远不会返回超时错误的。
身份认证
在访问网页的时候,有可能遇到这样的页面认证,可以使用Requests字典的身份认证功能。

更简便的认证,可以直接传一个元组,它会默认使用 HTTPBasicAuth 这个类来认证
Requests 还提供了其他的认证方式,如 OAuth 认证,不过需要安装 oauth 包
使用OAuth1方法认证
Prepared Request
当从 API 或者会话调用中收到一个 Response 对象时,request 属性其实是使用了 PreparedRequest。有时在发送请求之前,需要对 body 或者 header (或者别的什么东西)做一些额外处理。
引入 Request,然后用 url、data、headers 参数构造了一个 Request 对象,需要再调用 Session 的 prepare_request() 方法将其转换为一个 Prepared Request 对象,然后调用 send() 方法发送即可
有了 Request 这个对象,就可以将一个个请求当做一个独立的对象来看待,这样在进行队列调度的时候会非常方便
正则表达式
实战-抓取猫眼电影排行
任务
利用 Requests 和正则表达式来抓取猫眼电影 TOP100 。
提取出猫眼电影 TOP100 榜的电影名称、时间、评分、图片等信息,提取的结果以文件形式保存下来。
分析
打开猫眼电影可以查看榜单信息
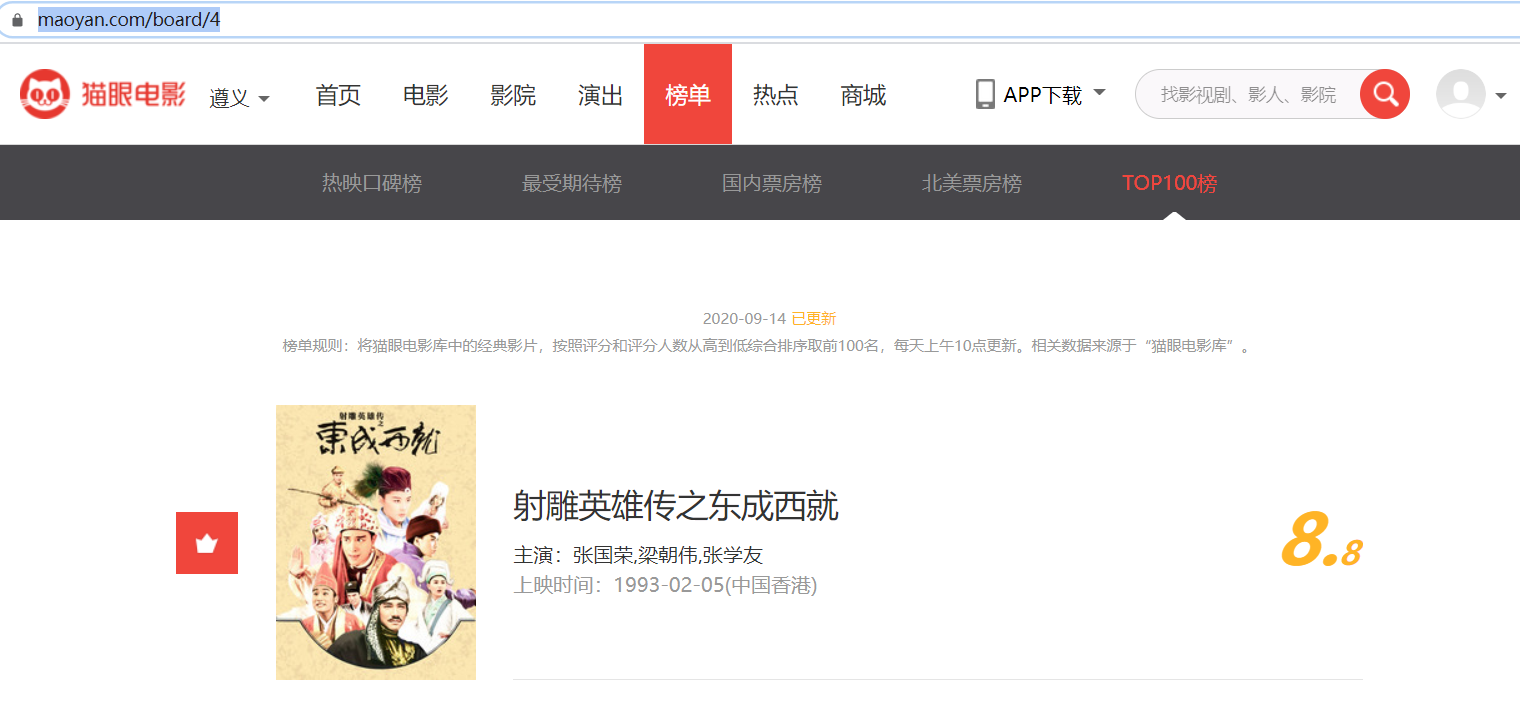
在图中可以清楚地看到影片的信息,页面中显示的信息有影片名称、主演、上映时间、上映地区、评分、图片等。
之后点击下一页,观察url的变化。
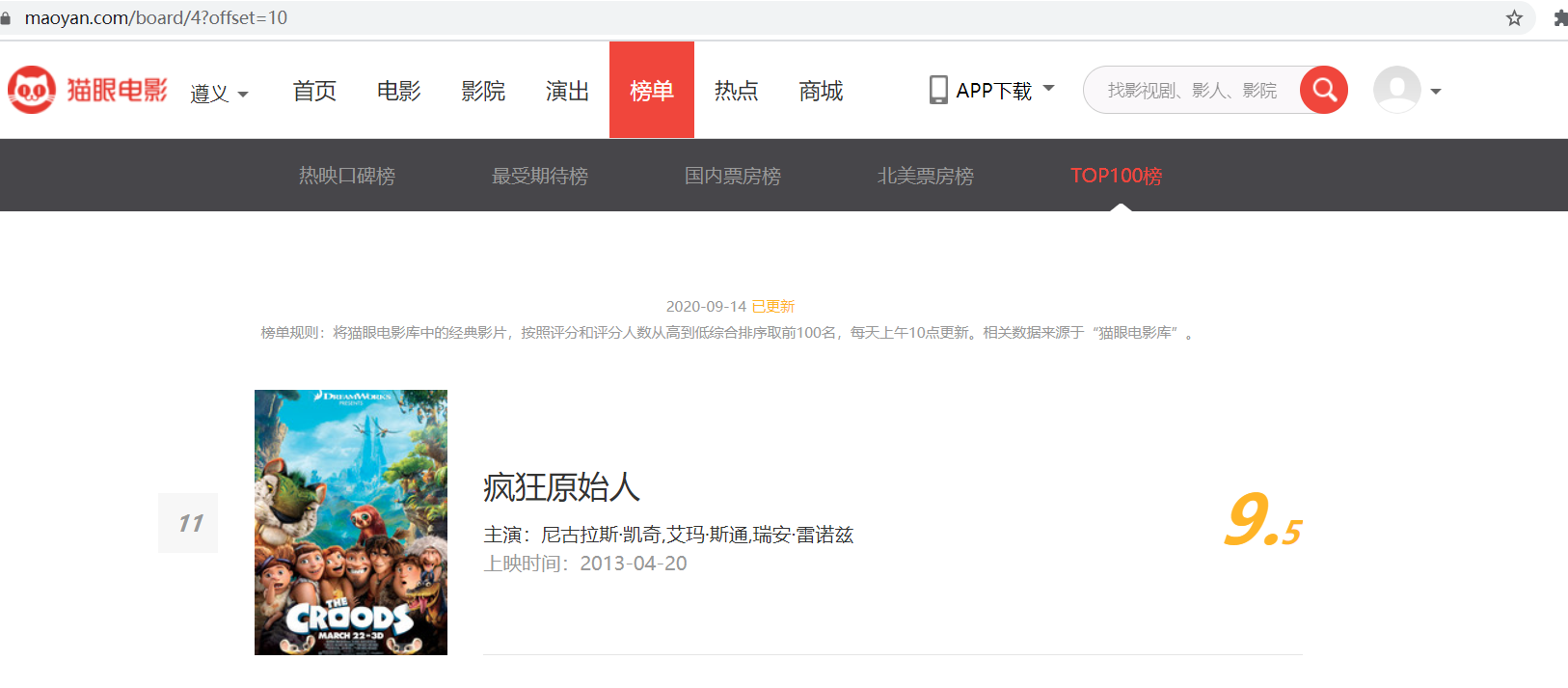

可以发现http://maoyan.com/board/4?offset=10比之前的url多了一个参数offset,参数值为10,目前显示的排行数据11~20,可以判断offset是一个偏移量的参数再点击下一页,发现页面的 URL 变成了:http://maoyan.com/board/4?offset=20,参数 offset 变成了 20,而显示的结果是排行 21-30 的电影。
可以判断offset是一个偏移量,如果偏移值为n,则当前页面的序号为n+1到n+10,这样就可以更根据offset获取top100的所有电影信息了。
抓取
抓取首页
定义一个get_frist_page()函数方法,实现抓取首页,代码实现,并通过str_to_dict()函数方法,解析headers。
一定要加上请求头,不然猫眼网站会禁止访问
使用正则提取数据
现在抓取了首页,需要进一步抓取相关信息,接下来回到网页看一下页面的真实源码,在开发者工具中 Network 监听,然后查看一下源代码,注意这里不要在 Elements 选项卡直接查看源码,此处的源码可能经过 JavaScript 的操作而和原始请求的不同,需要从Network选项卡部分查看原始请求得到的源码。

先看下个电影的相关内容
现在需要从这段里面提取需要的信息,书写正则表达式
这样就可以提取第一页的内容,代码如下:
运行结果:
由于数据看起来比较杂乱,需要处理一下,遍历生成为字典
存储数据
把数据存储到文本文件中,在这里直接写入到一个文本文件中,通过 json 库的 dumps() 方法实现字典的序列化,并指定 ensure_ascii 参数为 False,这样可以保证输出的结果是中文形式而不是 Unicode 编码。
实战-分析ajax爬取今日头条街拍美图
什么是Ajax
Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。
Ajax 请求:数据的加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后会会再向服务器请求某个接口获取数据,然后数据再被处理才呈现到网页上。
Ajax分析方法
查看请求
开发者工具(F12) > Network
过滤请求
点击XHR,筛选ajax请求

Ajax结果提取
分析请求
分析网址:https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
打开开发者工具 > Network面板>选中XHR,筛选ajax请求

分析url参数


可以后面多了一个offset参数在变化,偏移量为20。其中keyword为搜索关键字,count为显示的数据条数。
抓取
获取数据
获取图片
存储图片
主函数
启动
selenium
安装
但是需要用浏览器来配合selenium使用,需要进行一些配置,才可以使用selenium
ChromeDriver
下载
selenium对chrome浏览器操作,需要进行以下配置
根据chrome版本进行下载ChromeDriver。
根据版本号,找到对应下载版本

配置环境变量
之后将下载后,解压得到exe文件进行配置相关的环境变量。
在windows平台下,直接把可执行文件拖入python的Scripts目录下,这样就配置到环境变量中了
在 Linux、Mac 下,需要将可执行文件配置到环境变量或将文件移动到属于环境变量的目录里。
例如移动文件到 /usr/bin 目录,首先命令行进入其所在路径,然后将其移动到 /usr/bin:
当然也可以将 ChromeDriver 配置到 $PATH,首先可以将可执行文件放到某一目录,目录可以任意选择,例如将当前可执行文件放在 /usr/local/chromedriver 目录下,接下来可以修改 ~/.profile 文件,命令如下:
保存然后执行:
验证
在命令行下输入chromedriver命令进行验证

然后在程序中测试
如果有chrome浏览器自动打开,就代表配置成功。
GeckoDriver
下载
selenium对firefox浏览器操作,需要进行以下配置
配置环境变量
下载完成后将geckodriver可执行文件配置到环境变量中
在windows平台下,直接把可执行文件拖入python的Scripts目录下,这样就配置到环境变量中了
在 Linux、Mac 下,需要将可执行文件配置到环境变量或将文件移动到属于环境变量的目录里。
例如移动文件到 /usr/bin 目录,首先命令行进入其所在路径,然后将其移动到 /usr/bin:
当然也可以将 GeckoDriver 配置到 $PATH,首先可以将可执行文件放到某一目录,目录可以任意选择,例如将当前可执行文件放在/usr/local/geckodriver目录下,接下来可以修改 ~/.profile 文件,命令如下:
添加如下一句配置:
保存然后执行如下命令即可完成配置:
验证
在命令行下输入GeckoDriver命令进行验证

然后在程序中测试
如果有Firefox浏览器自动打开,就代表配置成功
PhantomJS
下载
PhantomJS是一个无界面的浏览器.selenium支持PhantomJS,这样在运行的时候就不会弹出一个浏览器。

配置环境变量
配置环境和前面一样
验证
在命令行下输入PhantomJS命令进行验证有类似结果输出就代表配置环境成功

然后在程序中测试
运行后会发现没有浏览器打开,但实际上phantomjs已经运行起来了
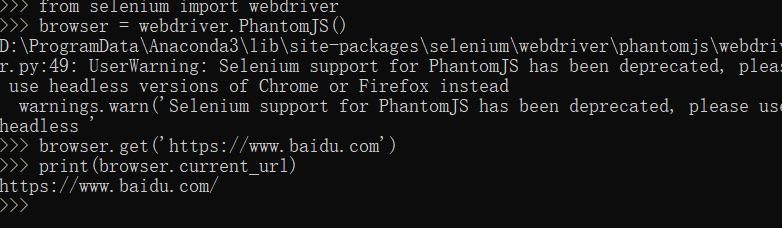
这里访问了百度,如果将当前url打印出来了就代表PhantomJS配置成功了
用途
selenium能够模拟用户打开浏览器,从而获取数据,能够解决动态渲染页面(ajax)的问题。
文档
用法
基本使用
导入模块
创建webdriver实例
发起请求
driver.get 方法将打开URL中填写的地址,WebDriver 将等待, 直到页面完全加载完毕(其实是等到”onload” 方法执行完毕),然后返回继续执行脚本。
查找元素
输入内容以及清除内容、按下enter键
关闭浏览器
如果想要浏览器一直显示,就不要输入这句。
点击
填写表单
测试网站
测试url
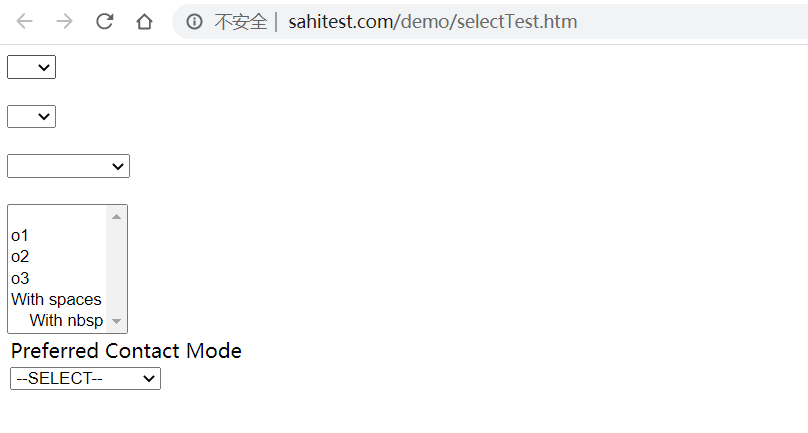

导入模块
Select类方法
options
返回属于此选择标记的所有选项的列表
选择
select_by_value
通过 value 值来获取 select 列表的标签名
select_by_index
通过 下标 来获取 select 列表的标签名
select_by_visible_text
通过 可见的文本内容 来获取 select
取消选择
deselect_by_index(index)
deselect_by_value(value)
deselect_by_visible_text(text)
deselect_all()
select框
实例
拖拽


切换窗口、框架
切换窗口

切换iframe框架


返回父frame:
访问浏览器历史记录
在浏览历史中前进和后退你可以使用:
操作cookies
添加cookies
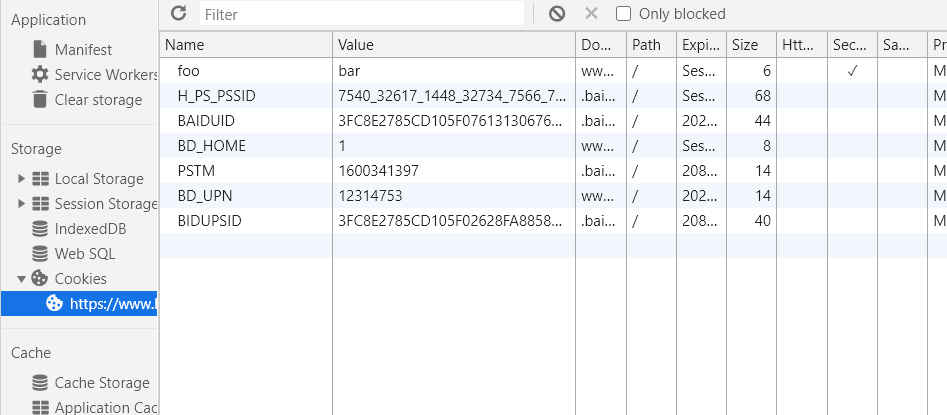
获取所有当前URL下可获得的Cookies
查找元素
driver.find_element_by_id()
通过ID查找元素
driver.find_element_by_name()
通过Name查找元素
driver.find_element_by_xpath()
通过XPath查找元素
driver.find_element_by_link_text()
通过链接文本获取超链接
driver.find_element_by_tag_name()
过标签名查找元素
driver.find_element_by_class_name()
通过Class name 定位元素
driver.find_element_by_css_selector()
通过CSS选择器查找元素
其中xpath用法
nodename
选取此节点的所有子节点
/
从当前节点选取直接子节点
//
从当前节点选取子孙节点
.
选取当前节点
..
选取当前节点的父节点
@
选取属性
*
通配符,选择所有元素节点与元素名
@*
选取所有属性
[@attrib]
选取具有给定属性的所有元素
[@attrib='value]
选取给定属性具有给定值的所有元素
[tag]
选取所有具有指定元素的直接子节点
[tag="text"]
选取所有具有指定元素并且文本内容是text节点
等待页面加载完成
现在的大多数的Web应用程序是使用Ajax技术。当一个页面被加载到浏览器时, 该页面内的元素可以在不同的时间点被加载。这使得定位元素变得困难, 如果元素不再页面之中,会抛出 ElementNotVisibleException 异常。 使用 waits, 可以解决这个问题。waits提供了一些操作之间的时间间隔- 主要是定位元素或针对该元素的任何其他操作。
Selenium Webdriver 提供两种类型的waits - 隐式和显式。 显式等待会让WebDriver等待满足一定的条件以后再进一步的执行。 而隐式等待让Webdriver等待一定的时间后再才是查找某元素。
显式等待
所有的加载条件
title_is
标题是某内容
title_contains
标题包含某内容
presence_of_element_located
节点加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located
节点可见,传入定位元组
visibility_of
可见,传入节点对象
presence_of_all_elements_located
所有节点加载出
text_to_be_present_in_element
某个节点文本包含某文字
text_to_be_present_in_element_value
某个节点值包含某文字
frame_to_be_available_and_switch_to_it frame
加载并切换
invisibility_of_element_located
节点不可见
element_to_be_clickable
节点可点击
staleness_of
判断一个节点是否仍在DOM,可判断页面是否已经刷新
element_to_be_selected
节点可选择,传节点对象
element_located_to_be_selected
节点可选择,传入定位元组
element_selection_state_to_be
传入节点对象以及状态,相等返回True,否则返回False
element_located_selection_state_to_be
传入定位元组以及状态,相等返回True,否则返回False
alert_is_present
是否出现Alert
隐式等待
如果某些元素不是立即可用的,隐式等待是告诉WebDriver去等待一定的时间后去查找元素。 默认等待时间是0秒,一旦设置该值,隐式等待是设置该WebDriver的实例的生命周期。
执行javascript
模拟执行javascript,使用execute_script()方法实现
获取节点信息
获取属性
使用get_attribute()方法来获取节点的属性
运行结果:
获取文本值
通过text属性获取文本信息
运行结果:
获取ID、位置、标签名、大小
id属性:获取节点id
location:获取节点再页面中的相对位置
tag_name:获取标签名称
size:获取节点的大小
运行结果:
异常处理
运行结果:
设置代理
连接无用户密码认证的代理
有用户名和密码的连接
设置header
设置phantomjs请求头
设置chrome请求头
细节
设置phantomjs-图片不加载
设置chrome为无界面浏览
browser.save_screenshot('baid.png'):保存当前页面
最后更新于
这有帮助吗?